
在了解决策树的参数之前我们可以先看看决策树
决策树
为了要将表格(数据)转化为一棵树,决策树需要找出最佳节点和最佳的分枝方法,对分类决策树来说,衡量这个最佳的指标叫做“不纯度”。现在使用的决策树算法在分枝方法上的核心大多是围绕在对某个不纯度相关指标的最优化上。不纯度是基于节点来计算的,树中的每个节点都会有一个不纯度,并且子节点的不纯度一定是低于父节点的。无论决策树模型如何优化,在分枝上的本质都还是追求某个不纯度相关的指标的优化。
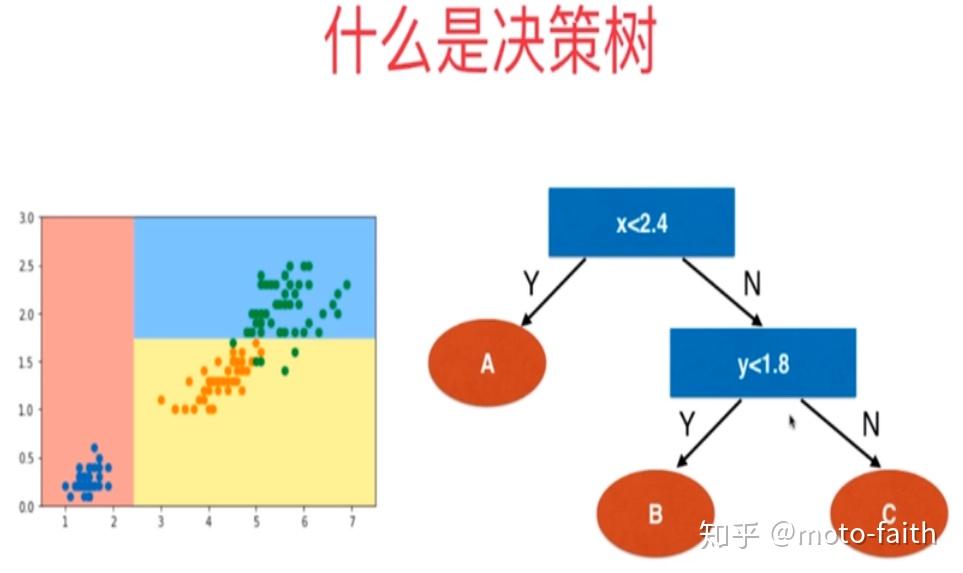
决策树参数
上文中提到的不纯度,在官方文档中提供了参数用来决定不纯度的计算方法,提供了两种选择:1)”“,使用信息熵();2)”gini“,使用基尼系数(Gini )。但是当我们使用如下代码建立决策树的时候就会发现如果我们用同一数据集复现这行代码,所得到的树会不相同;
clf = tree.DecisionTreeClassifier(criterion="entropy")score会在某个值附近波动,导致画出来的每一棵树都不一样。但是当我们引入参数,代码如下所示,最后得到的决策树就会一致。

clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30)在说明参数作用前我们先说明参数,是用来控制决策树中的随机选项的是干嘛用的,有两种值,输入”best",决策树在分枝时虽然随机,但是还是会优先选择更重要(按照不纯度设置的基尼系数或者信息熵的值)的特征进行分枝,输入“",决策树在分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。
正如我们之前提到的决策树模型是靠优化节点来建造一棵优化的树是干嘛用的,但最优的节点不一定可以得到最优树,于是选择建不同的树,然后从中取最好的,在每次分枝时不使用全部特征,随机选取一部分特征,从中选取不纯度相关指标最优的作为分枝用的节点,这样每次生成的树也就不同了。当随机选择特征,尤其是当在分枝时多个特征的不纯度相关指标一样时,就会随机选择一个作为分枝点,于是官方设计了参数决定特征选择的随机性,类似.seed(),保证同一个参数得到的决策树模型相同,实验结果可以复现,便于模型参数调优。
总结
是用来设置决策树分枝中随机模式的参数,在高维度时决策树的特征随机性会很明显,低维度的数据(比如鸢尾花数据集),随机性几乎不会显现。高维数据下我们设置并配合参数可以让模型稳定下来,保证同一数据集下是决策树结果可以多次复现,便于模型参数优化。





